现在轮到谷歌数到3了。
今日清晨,谷歌正式
发布了
Gemini 3系列模型,并首先上线Gemini 3 Pro预览版。依照介绍,开发者现可以在Google AI Studio直接调用API,Gemini运用已同步切换到新模型,企业与开发渠道侧的更新则也现已归入近期方案。对外而言,这次发布看似沿用了大模型迭代的惯常节奏,但从谷歌的表述方法到模型自身出现出来的才能,都暗示着一个趋势:Gemini 3不再只是参数与跑分的跃迁,而是在测验从头界说“模型在体系中的方位”。
Gemini 3 Pro被谷歌概括为三个中心改变:推理强度提高、现实共同性增强、多模态才能从规划之初就内置而非附加。这意味着模型在对话中处理文本、图画、音频、视频不再需求分阶段切换,而是以共同的方法了解信息结构。
官方给出的示例仍旧靠近日常场景:把家里几种言语混写的手写菜谱摄影丢给它,它能整理成一本共同格局的家庭菜谱;把一串长视频讲座交给它,它会把要害知识点拆成交互式卡片,乃至生成简略的可视化东西来辅佐回忆。在Gemini运用中,Canvas作业区可以支撑更完好的“小项目”;在Gemini Labs里,它也能依据你的问题生成相似杂志排版的界面。
这些特性看上去像是一次体会层面的晋级,但实在让Gemini 3 Pro与以往不同的,是它在各类评价中的体现出现了抢先式的改变,而不只是“稍微更准一点”。
曩昔一年,模型在各类基准测验中的距离往往停留在小范围动摇。现在,一些要害目标第一次被显着摆开。
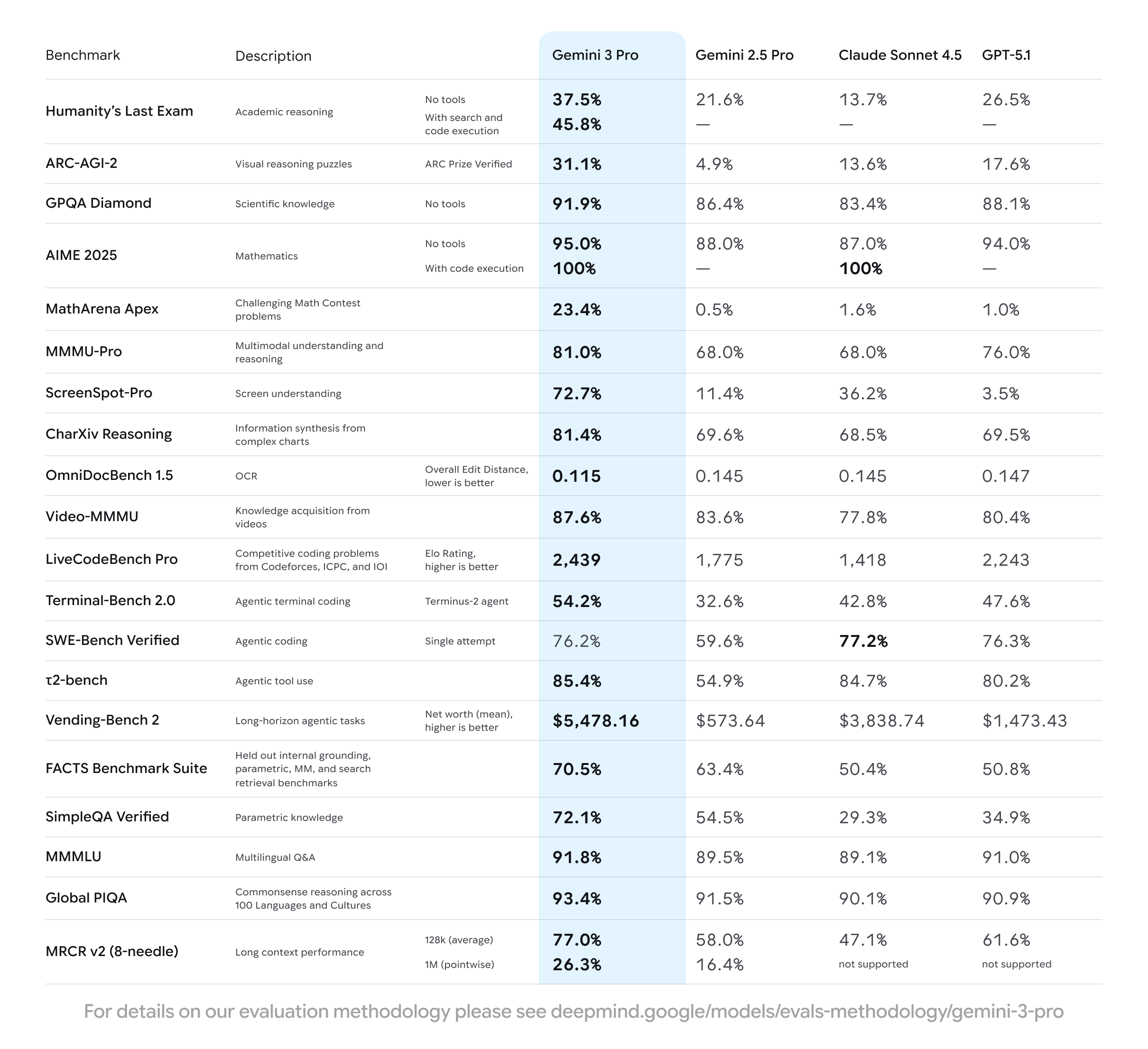
最杰出的体现落在高难度数学与杂乱推理方向。Gemini 3 Pro在MathArena Apex中拿到23.4%的正确率,而上一代模型为0.5%、Claude为1.6%、GPT-5.1为1.0%——这是长时间阻滞区间第一次被大幅打破。
在跨范畴推理考试中,这种距离继续扩展。例如在Humanity’s Last Exam中,Gemini 3 Pro的无东西得分到达37.5%,东西形式则提高至45.8%,高于上一代的21.6%和GPT-5.1的26.5%。在GPQA Diamond中,它也以91.9%抢先于同类模型的83%—88%区间。
多模态方面的改变则更会集体现在“界面了解”才能上。谷歌初次在技术资料中单列屏幕截图了解,模型不只能辨认内容,还能掌握界面结构、按钮层级与可操作区域。
在ScreenSpot-Pro中,Gemini 3 Pro到达72.7%,而GPT-5.1仅为3.5%,Claude为36.2%,上一代Gemini为11.4%。这儿的距离不只是辨认率问题,而是决议了Agent是在“凭感觉点击”,仍是的确了解界面语境。
这种才能直接关系到Agent在操作电脑时是否能坚持“情境认识”——能否根据界面判别接下来会产生什么。关于任何等待AI“完成使命”的体系而言,这类才能远比单纯的图画辨认更要害。
更广泛的体现也与谷歌想着重的方向共同:Gemini 3 Pro在多学科了解、视频推理和现实共同性上都摆开距离,并在工程类使命中显现出更高的安稳度。
例如在SimpleQA Verified中,Gemini 3 Pro到达72.1%,而同类模型遍及落在30%—35%区间;多言语归纳才能的MMLU中,它拿下91.8%,略高于GPT-5.1的91.0%,并抢先Claude的89.1%。
在工程类使命上,它不只能处理更杂乱的代码生成,还能在触及实践环境的测验中安稳履行。例如在Terminal-Bench 2.0中,Gemini 3 Pro到达54.2%,而Claude为42.8%,GPT-5.1为47.6%;在长链路使命Vending-Bench 2中,它的收益为5478美元,而其他模型遍及在1500—3800美元之间。
不过,Gemini 3实在有含义的部分,不在于单项才能的提高,而是谷歌环绕它构建的体系形状。随同此次更新推出的Antigravity,是一个以Agent为中心的开发环境。它并不是“补齐代码空缺”的东西,而是让模型可以直接参与开发流程:了解需求、拆分使命、生成代码、运转测验、查看界面作用,再回到代码层面调整。
于此,谷歌通过把不同模型组合运用,让Agent在编辑器、终端与浏览器之间自在切换,然后接受一段完好的履行链。关于结构不算杂乱的项目,它现已能承担起实践作业。
面向普通用户的改变,则更会集体现在Gemini运用和Google查找上。Gemini 3 Pro从第一天起便是默许模型,而运用内的“Gemini Agent”可以处理多步决议计划使命,例如归档邮件、组织行程或处理需求重复查找信息的业务。查找端的AI Mode也开端出现更动态的信息布局,包含结构化数据、图片、时间轴乃至交互组件。这些改变来自于Gemini 3对查询的拆分与重组,再由生成式界面组合展现,背面依靠的是更强的目的了解才能。
此外,谷歌在这一代模型中自动着重了一个方向:Gemini 3 Pro在答复时更少投合用户,而更倾向于提供有信息密度的反应。“下降投合性”既对应本年的对话安全评论,也阐明谷歌正在测验把“内容质量”变成产品特性,而不是言语风格。
根据上述这些,不难发现,Gemini 3的含义并不只是在于“跑分抢先多少”,而更多的是,它把才能从头组织成一个能坚持履行使命、能跨模态整合、能在实在环境中坚持结构安稳的体系。对谷歌来说,这提出了一个与GPT系列不同的答复:AI不只要强,更要稳;不只要会生成,更要懂场景;不只能了解界面,更要能在界面中继续举动。
当然,接下来,Gemini 3可以走多远,所依仗的远非这些看起来很漂亮的跑分和才能,而是在日常运用中,能有多少实在留得住的当地。